我们在进行生信分析时经常要处理大文件,如果用串行运算往往费时,所以需要并行运算以节省时间。目前,流行的生信工具通常都可以并行运算,比如bwa。通常来讲,我们进行并行运算可以选择多线程或者多进程。那么二者有什么差别呢,我们又该如何选择呢?
不同编程语言中的多线程和多进程实现机制是不一样的,其实我们不关心实现机制,我们关注的是实际的性能。本文以python语言为例,用一个测试脚本来比较python中多线程和多进程的性能区别。我们主要关注运行时间和内存占用情况。
我们知道,python中常用的多线程模块是threading,常用的多进程模块是multiprocessing。我们的测试脚本要解决的是一个运算量比较大的任务,根据是否(并行)运算以及使用哪种并行运算可以分为四种情形:
- 不进行计算
- 串行运算
- 多线程运算
- 多进程运算
得到的结果如下:
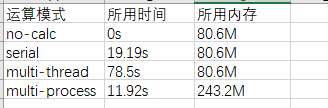
从中可以看出,对这个运算任务以及测试脚本而言,与串行运算相比,多线程所用的时间多很多,所占的内存一样;而多进程所用的时间变少(大约是串行运算时间的一半),所占用的内存变大(大约是串行运算的三倍)。
上述结果值得讨论的有两个:
为什么python中多线程运算所用的时间比串行运算还多?
这是因为python中GIL(Global Interpreter Lock)的存在使得对一个进程而言,不管有多少线程,任一时刻,只会有一个线程在执行。对于CPU密集型的线程,由于系统调度等其它时间花销,其效率不仅仅不高,反而有可能比较低[1]。也就是说,python中的多线程运算不能算作真正的并行运算。上面例子中的任务正好是一个CPU密集型任务,所以用多线程运算的时间反倒比串行运算还多。
为什么多线程运算占用的内存和串行运算一样,而多进程所用内存比串行运算大很多?
这是一个正常的结果,是由线程和进程的特点决定的。简单来说,线程会共享所属进程的内存资源,所以不会有额外的内存占用;而子进程会从父进程那里拷贝一份内存资源,所以每多一个子进程,就会多一份内存资源的拷贝,占用的内存就多了,上面的例子中共有两个子进程,所以就会多出来两份内存拷贝,看起来所占用的内存就是串行运算的三倍。(所用的术语只是为了阐述方便而用,可能有不恰当的地方)
综上,由于生信分析大多是CPU密集型(计算密集型)的任务,如果你用python来处理此类任务,多进程并行运算可能更适合。
参考
[1] https://www.cnblogs.com/yssjun/p/11302500.html
所用的测试脚本如下:
#!/usr/bin/python
from threading import Thread
from multiprocessing import Process
import time
import sysdef test_func(n):
for _ in range(n):
for i in a:
j = i + 1
print ja = [1] * 10000000 # 10M
ncore = 2
per_run = 20
total_run = ncore * per_runif __name__ == "__main__":
start_time = time.time()
if len(sys.argv) < 2:
print "Usage: python %s <no-calc | serial | multi-thread | multi-process>" % sys.argv[0]
sys.exit(1)
cores = None
if sys.argv[1] == "no-calc":
time.sleep(1)
elif sys.argv[1] == "serial":
test_func(total_run)
elif sys.argv[1] == "multi-thread":
cores = [Thread(target = test_func, args=(per_run, )) for _ in range(ncore)]
elif sys.argv[1] == "multi-process":
cores = [Process(target = test_func, args=(per_run, )) for _ in range(ncore)]
else:
print "Usage: python %s <no-calc | serial | multi-thread | multi-process>" % sys.argv[0]
sys.exit(3)
if cores:
for cr in cores:
cr.start()
for cr in cores:
cr.join()
end_time = time.time()
print end_time - start_time
我们用python分别创建多线程和多进程,然后打印出其中的变量和函数的id。这里的id是指python中对象的唯一标识符,可以通过id(obj)函数获得。如果两个对象的值相等,它们不一定是同一个对象,即它们的id不一定相等;反过来说,如果“两个”对象的id一样,那么它们其实是同一回事,就是同一个对象,它们的值一定相等。
我们首先用python创建多线程并打印其中对象的id。代码如下:
from threading import Thread
import time# all subthreads share data.
def run_subthread(thread_id):
time.sleep(thread_id + 1)
print("inside run_subthread: a = %d, id(a) = %d, id(run_subthread) = %d" % (a, id(a), id(run_subthread)))a = 10
print("outside run_subthread: a = %d, id(a) = %d, id(run_subthread) = %d" % (a, id(a), id(run_subthread)))if __name__ == "__main__":
threads = [Thread(target=run_subthread, args=(idx, )) for idx in range(2)]
for t in threads:
t.start()
for t in threads:
t.join()
print "all done"
运行结果如下:

从中可以看出,不同线程中的对象id是一样的,也就是说多线程共享了同一份对象资源。
然后我们用python创建多进程并打印其中对象的id。代码如下:
from multiprocessing import Process
import time# each subprocess has its own copy of data.
def run_subproc(proc_id):
time.sleep(proc_id + 1)
print("inside run_subproc: a = %d, d(a) = %d, id(run_subproc) = %d" % (a, id(a), id(run_subproc)))a = 10
print("outside run_subproc: a = %d, id(a) = %d, id(run_subproc) = %d" % (a, id(a), id(run_subproc)))if __name__ == "__main__":
proc = [Process(target=run_subproc, args=(idx, )) for idx in range(2)]
for p in proc:
p.start()
for p in proc:
p.join()
print "all done"
运行结果如下:
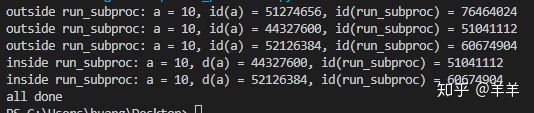
从中可以看出,不同子进程中的对象id是不一样的(变量和函数的id都不一样),说明多进程中,每个子进程都拷贝了父进程的一份对象资源。
除此之外,我们还可以看到,与多线程不同的是,多进程中的每个子进程都还执行了print("outside run_subproc: a = %d, id(a) = %d, id(run_subproc) = %d" % (a, id(a), id(run_subproc)))这一句。关于这一点的机制笔者并不完全清楚,不过它提醒我们,如果我们用python的多进程,要注意一些目标函数(target)之外的语句也可能会被执行,这并不是我们所期望的。
评论(0)